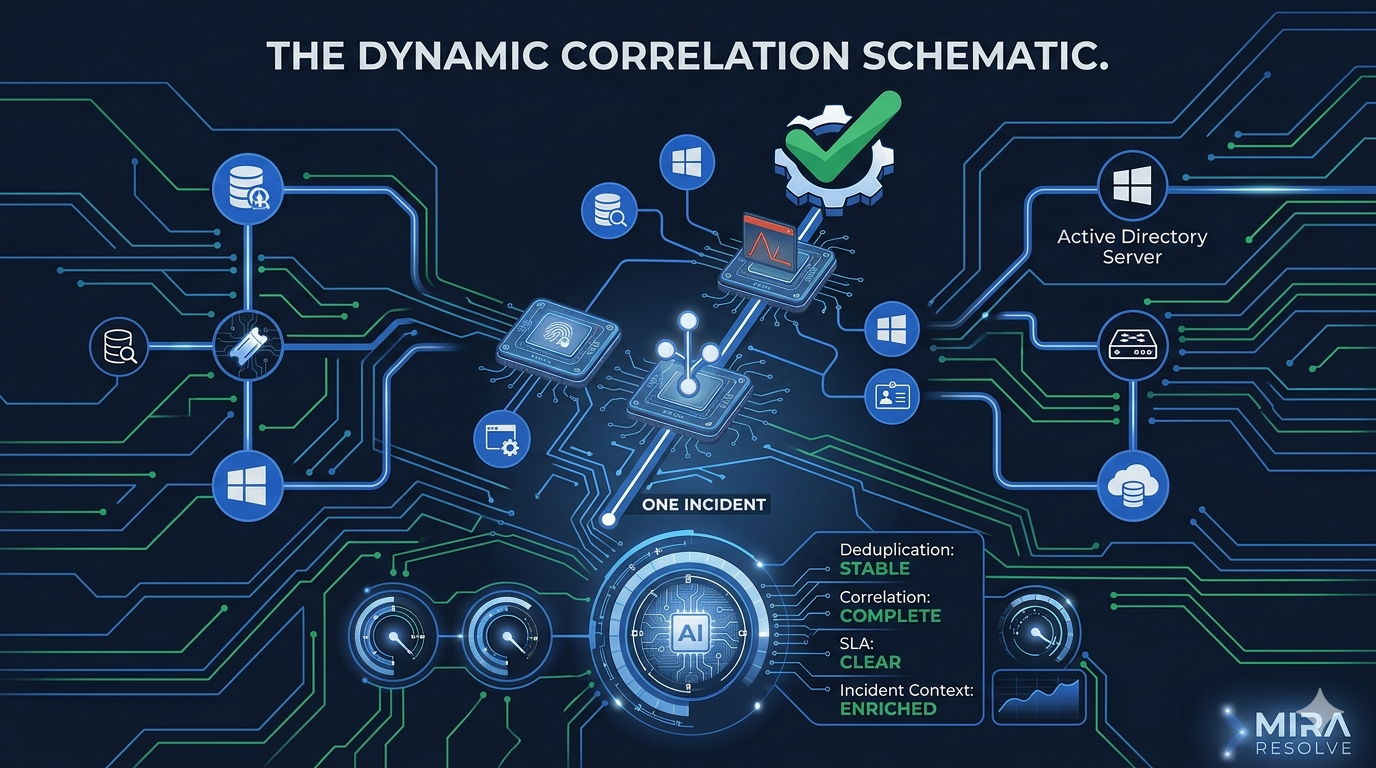
Every operations team I've worked with has the same version of this story. A disk fills up on a production server. The monitoring tool fires an alert. Then the dependent service fails its health check, and that fires another alert. Then the load balancer detects the unhealthy node and fires a third. Then the application monitoring catches elevated error rates and fires a fourth. Four alerts. Four tickets. Four notifications. One problem.
Multiply that by every server, every service, every environment. On a bad day, a single root cause can generate dozens of tickets. Your on-call engineer isn't investigating and resolving. They're triaging, deduplicating, and closing tickets that all describe the same underlying failure.
That's not an alert volume problem. It's an architecture problem.

How We Got Here
Traditional ITSM platforms were built with a straightforward model: something happens, create a ticket. That model works fine when tickets come from humans. A user calls, describes a problem, a ticket gets created. One user, one problem, one ticket.
Monitoring tools broke that model. They generate alerts programmatically, at machine speed, with no awareness of what other tools are also alerting on the same issue. Each monitoring source operates independently. Azure Monitor sees an infrastructure problem. PagerDuty sees an availability problem. Datadog sees a performance problem. They're all looking at the same outage from different angles, and each one creates a separate ticket.
The result is one-alert-one-incident sprawl. Your ticket queue fills up with duplicate reports of the same issue, your SLA timers start ticking on each one independently, and your team spends the first 30 minutes of every major incident just figuring out which tickets are the same problem.
Why More People Don't Fix It
The standard response is to add headcount. More people on call, more eyes on the queue, faster triage. But adding people to a broken architecture just means more people doing the wrong work. The issue isn't that your team is slow. It's that they're doing work the platform should be doing: correlating alerts, deduplicating tickets, linking related incidents, and identifying the root cause underneath the noise.
Some teams try to fix it with automation rules. "If alert contains 'disk space' and server matches pattern X, merge with existing ticket." These rules work until they don't. They're brittle, maintenance-heavy, and break every time the monitoring tool changes its payload format or a new alert type appears. You end up maintaining a parallel rule engine that nobody fully understands.
What Alert Correlation Actually Solves
Real alert correlation does three things that manual triage and rule-based automation can't:
Deduplication at ingestion. When the same alert fires multiple times from the same source (retries, flapping, monitoring tool weirdness), the second and third firings should add context to the existing ticket, not create new ones. This requires a stable fingerprint, a way to identify that two alerts describe the same condition even if the payload isn't byte-identical.
Cross-source linking. When Azure Monitor, PagerDuty, and Datadog all fire on the same underlying issue, the platform should recognize they're related and group them into a single incident. This is harder than deduplication because the alerts come from different sources with different schemas. It requires understanding what the alerts are about, not just pattern-matching on fields.
Lifecycle management. When the monitoring tool sends a resolve signal, the linked ticket should close automatically. When the same alert flaps repeatedly (fires, resolves, fires again), the platform should recognize the pattern and escalate to a problem record that tracks the underlying instability. When a maintenance window is scheduled, alerts from affected resources should be held, not ticketed.
The Flap Problem
Flapping is one of the most under appreciated sources of alert fatigue. A service hovers at the edge of its health threshold. It fires an alert. It recovers. The alert resolves. Thirty seconds later, it fires again. Each cycle creates a new ticket if the platform doesn't track alert state.
Mature alert correlation tracks flap counts. After a configurable threshold, the platform stops creating new incident tickets and instead spawns a problem record. That problem record says: this alert has fired and resolved 15 times in the last hour. The underlying cause isn't the individual failure. It's the instability.
That's a fundamentally different workflow than "create a ticket every time the threshold is breached." It turns noise into signal and gives your team something actionable instead of a queue full of transient incidents.
Maintenance Windows
Planned outages generate predictable alert noise. You're patching a server. The monitoring tool sees it go down. Alert fires. Ticket created. On-call engineer gets paged. They look at the ticket, see the maintenance window on the calendar, close the ticket, and go back to what they were doing.
Real alert correlation integrates maintenance windows into the alert lifecycle. Alerts from resources under maintenance get placed on hold automatically. When the window expires, any alerts that are still firing get reactivated. No false pages, no wasted triage time, no noise.
What Changes
When alert correlation works, the visible change is that your ticket queue gets quieter. Five alerts from one outage become one incident. Flapping services generate problem records instead of ticket floods. Maintenance windows stop generating noise.
The less visible change is in your team's posture. They stop spending the first phase of every incident figuring out what's happening and start spending it on resolution. The cognitive load drops. The mean time to resolution drops with it. And when you look at your SLA reports, you're measuring actual incidents against actual targets instead of counting the same outage five times across five tickets.
Alert fatigue isn't a people problem. It's a systems problem. Fix the system and the fatigue goes away.
Mira Resolve includes a native alert correlation engine with structured ingestion from Azure Monitor, PagerDuty, Datadog, and custom webhooks. Deduplication, cross-source correlation, flap detection, and maintenance windows are built into the platform. Learn more at Mira Resolve.